Databricks Architecture Overview
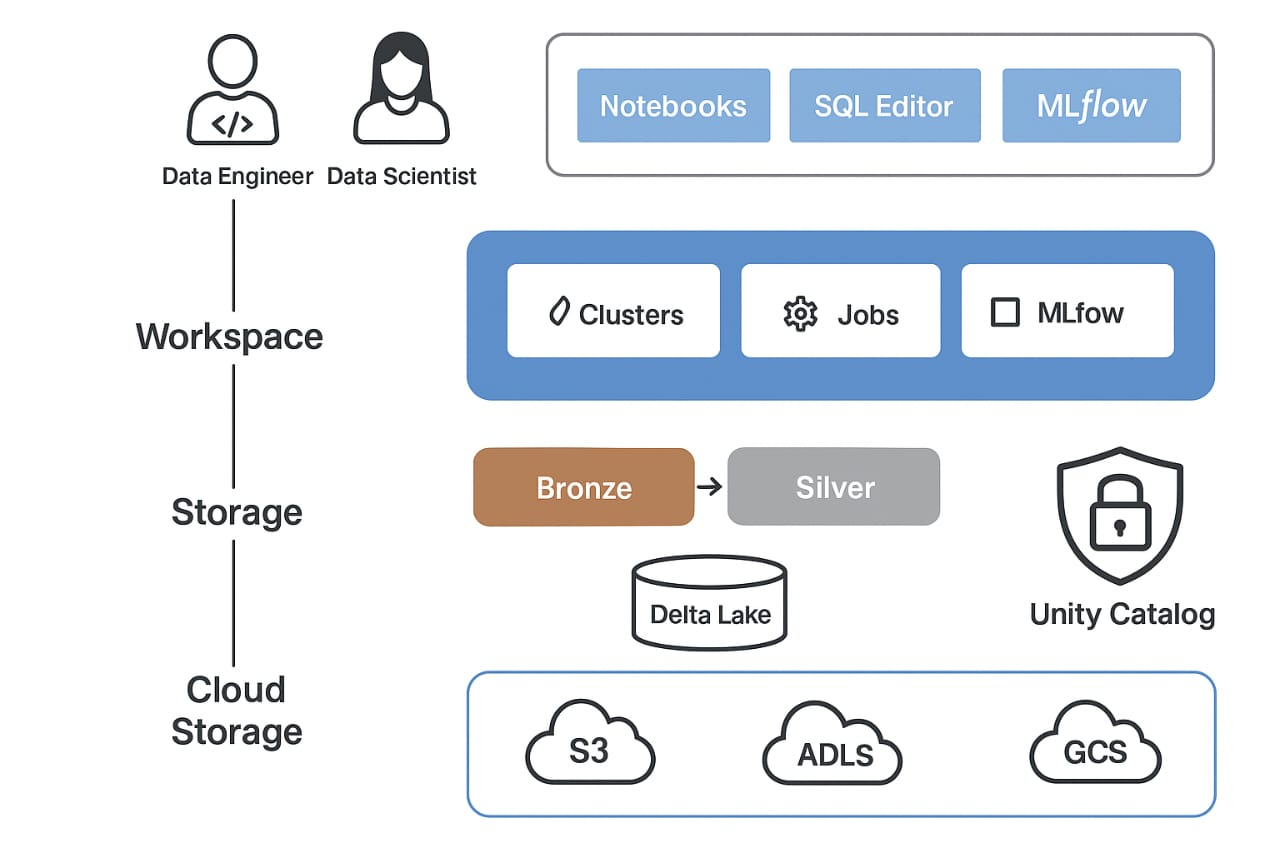
How to Start with Databricks Architecture – Step by Step
1. Understand the Core Components
Before setting it up, know what makes up the Databricks platform:
| Component | Purpose | Modern Story (Usage Scenario) |
|---|---|---|
| Workspace | User interface for managing notebooks, jobs, clusters, and more. | A data analyst logs in, opens a notebook, checks job status, and explores datasets from one place. |
| Cluster | Group of virtual machines running your code using Spark. | A data engineer spins up a cluster to process a large batch of sales data using Spark. |
| Notebook | Interactive coding environment (like Jupyter). | A data scientist tests different ML models in a notebook and visualizes accuracy results live. |
| Jobs | Scheduled workflows like ETL pipelines or ML training. | An ML engineer schedules a nightly job to retrain a recommendation model with fresh data. |
| Delta Lake | Storage layer with ACID transactions and versioning. | A team rewinds to a previous dataset version to fix a report after a faulty data load. |
| Databricks SQL | SQL-based query engine for BI and dashboards. | A business analyst creates a real-time dashboard showing daily revenue using SQL queries. |
| Unity Catalog | Centralized governance, access control, and data catalog. | A data steward assigns fine-grained permissions to datasets across departments securely. |
2. Storage Layer(Delta Lake + DBFS -> Lakehouse)
Cloud Storage (S3 / ADLS[AZURE DATA LAKE STORAGE] / GCS[GOOGLE CLOUD STORAGE]):
Base layer for storing raw and processed data.
DBFS (Databricks File System):
A virtual file system that simplifies access to cloud storage within Databricks.
Delta Lake:
Adds reliability and performance with:
- ACID transactions for data integrity
- Schema enforcement for clean data
- Time travel to access previous versions
- Streaming support for real-time use cases
A retail company stores order data in cloud storage. Databricks uses DBFS to access this data easily, while Delta Lake ensures it’s clean, reliable, and recoverable. Analysts can run real-time queries, and engineers can safely update data without conflict.
3. Medallion Architecture (Data Layers)
Bronze Layer:
Raw data is ingested from sources like APIs, logs, or databases — no changes made.
Silver Layer:
Data is cleaned, filtered, and structured — ready for analysis.
Gold Layer:
Data is transformed into business-friendly formats — includes KPIs, dashboards, and ML features.
Modern Story (Short & Clear)A ride-sharing company collects raw trip data (Bronze). Engineers clean and join it with driver and rider info (Silver). Analysts use the final dataset to track daily revenue and surge pricing insights (Gold).
4. Security & Governance in Databricks
Authentication & Authorization:
Controls who can access what (users, roles, cluster policies).
Unity Catalog:
Centralized data governance — manage permissions, track data lineage, and enable auditing.
Encryption:
Data is secured at rest and in transit to protect sensitive information.
Modern Story (Short & Clear)A healthcare company uses Databricks to process patient data. Only authorized users can access sensitive datasets, enforced by Unity Catalog. All data is encrypted, and every access is logged for compliance and audits.
5. ML & Advanced Features
MLflow:
Tracks ML experiments, manages model versions, and supports deployment.
Feature Store:
Central repository for reusable ML features across teams and projects.
Streaming (Structured Streaming):
Build real-time data pipelines for instant insights and live model inference.
Modern Story (Short & Clear)A fintech company builds fraud detection models. Data scientists track experiments with MLflow, reuse customer behavior features from the Feature Store, and deploy the model on a real-time streaming pipeline to catch fraud instantly.
6. Cloud-Native Integration
Databricks runs on:
AWS, Azure, or GCP — leveraging the scalability and flexibility of the cloud.
Integrates with Native cloud services like:
Storage: S3, ADLS, GCS etc..
Messaging: Event Hubs, Pub/Sub etc..
Data Warehouses: Redshift, Synapse, BigQuery etc..
Identity & Access: IAM, Azure AD
Modern Story (Short & Clear)A media company runs Databricks on Azure, ingests real-time clickstream data from Event Hubs, stores it in ADLS, and applies access controls using Azure AD. The same data is later queried from Synapse Analytics for reporting.
7. Performance & Optimization
Caching & Query Optimization:
Speeds up repeated queries automatically.
Delta Lake Optimizations:
Use commands like OPTIMIZE and Z-ORDER to boost read/write performance.
Photon Engine:
High-speed, vectorized query engine for blazing-fast SQL performance.
Auto-scaling & Cost Control:
Clusters scale up or down based on workload, optimizing both performance and cost.
Modern Story (Short & Clear)An e-commerce company analyzes billions of transactions daily. Photon Engine accelerates their dashboard queries, Z-ORDER improves filtering on key columns, and auto-scaling clusters ensure they never overpay during off-hours.
🔑 1-Minute Summary
Databricks: Unified cloud platform for data engineering, analytics, and AI.
Built on: Cloud storage (S3, ADLS, GCS) with Delta Lake for reliable data management.
Core: Workspace + Spark clusters + collaborative notebooks + jobs scheduler.
Medallion Architecture: Bronze (raw) → Silver (cleaned) → Gold (business-ready) data layers.
Security: Strong access control via Unity Catalog + encryption + governance.
ML & Streaming: MLflow for model lifecycle + Feature Store + real-time pipelines.
Cloud-Native: Integrates seamlessly with AWS, Azure, GCP services.
Performance: Auto-scaling, caching, Delta optimizations, Photon engine for speed.