Data Pipeline Overview
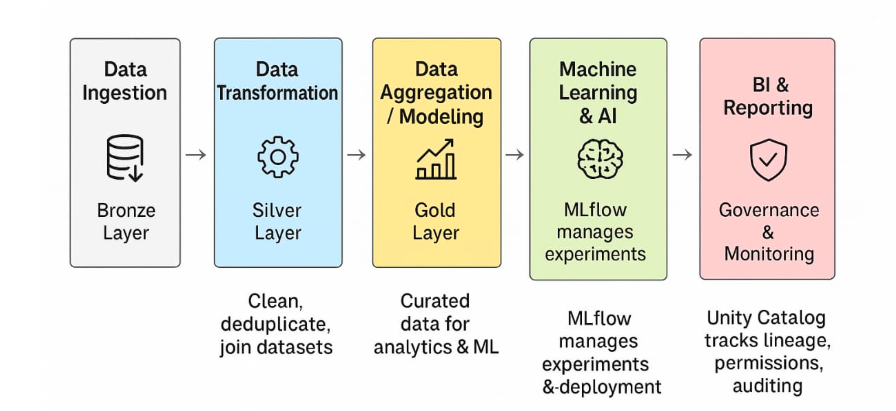
Step-by-Step: How Data Moves Through Databricks
Step 1: Data Ingestion
Professional Explanation:
This is the first stage of the data pipeline where raw data enters the Databricks Lakehouse platform.
Sources: Data can arrive from multiple upstream systems like REST APIs (e.g., weather or pricing APIs), transactional databases (e.g., PostgreSQL, MySQL), streaming sources (e.g., Kafka, IoT sensors), cloud storage (e.g., S3, ADLS), or even real-time logs.
Storage Target: The ingested data is stored in the Bronze Layer, which holds raw, unprocessed data in its original format.
Purpose: The Bronze Layer acts as a single source of truth. It allows teams to reprocess data if needed and serves as an audit-friendly historical archive.
Modern, Memorable Story:
Imagine an e-commerce app like Amazon during Black Friday.
Every time a customer adds an item to their cart, places an order, or updates their address — that activity generates events.
These events are sent in real time via Kafka streams and REST APIs into Databricks every few seconds. Databricks ingests this data and stores it as-is in the Bronze Layer, ensuring no information is lost — even if it’s dirty, duplicated, or out-of-order.
Key Concepts to Remember:
- Bronze = Raw & Immutable
- Captures everything, good or bad
- Enables replayability, auditing, and flexibility for downstream transformation
- Ingestion supports batch or real-time streaming
Step 2: Data Transformation
Professional Explanation:
This stage focuses on making raw data usable.
- Clean invalid or missing values (e.g., remove nulls, standardize formats).
- Deduplicate repeated records.
- Join data from multiple sources (e.g., transactions + user profiles).
- Normalize or enrich the data (e.g., adding geo-tags from ZIP codes).
- The transformed, quality-checked data is stored in the Silver Layer.
Silver Layer = Cleaned & Structured Data, optimized for analysis and machine learning.
Modern, Memorable Story:
Think of a food delivery app like DoorDash or Zomato.
Raw data from restaurants, delivery partners, and customers arrives in messy, inconsistent formats.
One restaurant sends prices as strings (“$12.50”), another as floats (12.5).
Some customer records have missing phone numbers.
Duplicate orders appear due to payment retries.
In the Silver Layer, data engineers:- Remove bad records (e.g., null locations)
- Standardize formats (e.g., unify currency/units)
- Merge datasets (e.g., orders + customer reviews)
- The result? A clean, consistent, and trusted dataset ready for analytics, reports, and ML.
Key Concepts to Remember:
- Silver = Trusted Data
- Focus on quality, consistency, and structure
- Enables downstream use cases like BI and ML with minimal rework
- Often the layer most used by data analysts and scientists
Step 3: Data Aggregation & Modeling
Profesional Explanation:
This stage is all about creating business-ready, curated datasets designed for specific use cases.
- Aggregated (e.g., daily sales totals, average delivery times)
- Filtered or grouped by dimensions (e.g., by region, product, customer segment)
- Modeled into meaningful structures (e.g., star/snowflake schemas for reporting)
- The results are stored in the Gold Layer, which contains high-quality, ready-for-use data tailored for dashboards, analytics, and ML training.
Gold = Business-Optimized Data — clean, fast, and query-ready.
Modern, Memorable Story:
Imagine a global fitness app like Peloton.
They collect tons of cleaned data from workouts, user profiles, and app activity (from Silver).
- Aggregate total workout hours per country, per week
- Model revenue by subscription plan and device type
- Segment users by retention behavior, workout types, or classes taken
- This curated dataset powers dashboards for execs to view monthly trends, compare regions, and forecast demand. It also fuels ML models like predicting churn or recommending classes.
Key Concepts to Remember:
- Gold = Curated, Analytics-Ready
- Optimized for speed, clarity, and usability
- Powers dashboards, KPIs, and ML models
- Represents “single source of business truth”
Step 4: Machine Learning & AI
Professional Explanation:
This stage leverages the curated Gold Layer data to build, train, and deploy machine learning models.
- Train predictive models (e.g., churn prediction, demand forecasting)
- Experiment and track model versions using tools like MLflow
- Deploy models for real-time or batch scoring
- MLflow manages the end-to-end ML lifecycle — from experiment tracking to model deployment and monitoring.
- The goal is to extract actionable intelligence and automate decision-making.
Modern, Memorable Story:
Consider a popular streaming service like Netflix or Spotify.
Using the Gold Layer data on user behavior, watch history, and engagement, data scientists train a recommendation engine to personalize content for each user.
MLflow tracks multiple model versions — testing which algorithms better predict what shows a user will love.
Once the best model is identified, it’s deployed to production, powering real-time recommendations on the app, boosting user engagement and retention.
Key Concepts to Remember:
- ML uses high-quality, curated data from Gold Layer
- MLflow enables experiment tracking, reproducibility, and deployment
- Models turn data into predictive insights and automation
- Supports use cases like churn prediction, personalization, fraud detection, and more
Step 5: BI & Reporting
Professional Explanation:
At this stage, curated data and ML insights are delivered to business users through interactive dashboards and reports.
Business Analysts and decision-makers use Databricks SQL, or connect external BI tools like Power BI, Tableau, or Looker.
- Real-time dashboards
- Custom reports
- Ad hoc analyses
- The goal is to empower teams with up-to-date, actionable insights for strategic and operational decisions.
Modern, Memorable Story:
Picture a global logistics company like FedEx or DHL.
Executives need to track daily shipment volumes, delivery times, and fleet performance across continents.
Using Databricks SQL and Power BI dashboards connected to the Gold Layer, they get real-time updates on key metrics.
This enables fast decisions — rerouting shipments, managing fleet allocation, and responding quickly to delays — all based on fresh, reliable data.
Key Concepts to Remember:
- BI tools connect seamlessly to the curated Gold Layer
- Enables real-time, interactive decision-making
- Supports a wide range of users — from executives to analysts
- Translates data and ML insights into business value
Step 6: Governance & Monitoring
Professional Explanation:
This stage ensures that data is secure, compliant, and reliable throughout its lifecycle.
- Data lineage (tracking data origin and transformations)
- Access controls and permissions (who can see or modify data)
- Audit logs for compliance and security reviews
- Detect pipeline failures or delays
- Monitor data quality and freshness
- Notify teams for quick incident response
This ensures trustworthy data pipelines and protects sensitive information.
Modern, Memorable Story:
Imagine a healthcare provider managing patient data across multiple hospitals.
With strict privacy laws like HIPAA, they need to ensure that only authorized staff access sensitive records.
Unity Catalog tracks exactly where each piece of data came from and who accessed it — providing a clear audit trail.
Meanwhile, automated alerts notify the data team immediately if any data pipeline breaks or if unusual access patterns occur, ensuring patient data is always secure and pipelines run smoothly.
Key Concepts to Remember:
- Governance = Security, Compliance, Transparency
- Unity Catalog tracks lineage, permissions, and auditing
- Monitoring enables proactive issue detection and resolution
- Builds trust in the data platform and meets regulatory requirements
🔑 1-Minute Summary
Step 1: Data Ingestion
Data ingested from APIs, databases, IoT streams into Bronze Layer (raw, immutable).
Step 2: Data Transformation
Cleaned, deduplicated, and joined data stored in Silver Layer (trusted & structured).
Step 3: Data Aggregation & Modeling
Curated datasets for analytics and ML stored in Gold Layer (business-ready).
Step 4: Machine Learning & AI
ML models trained on Gold data, managed and deployed with MLflow.
Step 5: BI & Reporting
Business Analysts use Databricks SQL or connect Power BI/Tableau for real-time dashboards.
Step 6: Governance & Monitoring
Unity Catalog handles lineage, permissions, auditing; jobs and alerts monitor pipelines.