Centralized vs Distributed Processing
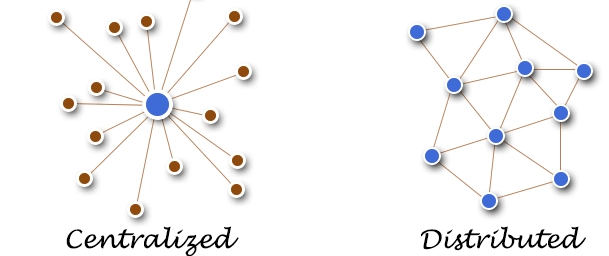
If you don’t understand Centralized vs Distributed Processing, you don’t understand modern data systems.
👉 This is a fundamental architectural decision:
- Centralized → Single system handles everything
- Distributed → Multiple systems share the workload
What is Centralized Processing?
Centralized Processing means:
- All computation happens in a single system
- One machine handles:
- Storage
- Processing
- Queries
Examples
- Traditional databases
- Single-node applications
Key Idea
👉 Simple but limited
Centralized Flow
Users → Single Server → Processing → Output
What is Distributed Processing?
Distributed Processing means:
- Workload is split across multiple machines (nodes)
- Systems work together to process data
Examples
- Spark
- Hadoop
- Distributed databases
Key Idea
👉 Scale horizontally
Distributed Flow
Users → Cluster → Parallel Processing → Output
Centralized vs Distributed (7 Real Differences)
| Feature | Centralized Processing | Distributed Processing |
|---|---|---|
| Architecture | Single node | Multiple nodes |
| Scalability | Limited | Highly scalable |
| Performance | Limited by hardware | Parallel processing |
| Fault Tolerance | Low | High |
| Complexity | Low | High |
| Cost | Lower (initial) | Higher (setup) |
| Use Case | Small systems | Big data systems |
Data Processing Architecture (Critical 🔥)
Centralized Architecture
- Vertical scaling (increase CPU/RAM)
- Single point of failure
- Easier to manage
👉 Example:
- One database server handling all queries
Distributed Architecture
- Horizontal scaling (add nodes)
- Fault-tolerant
- Data partitioning & parallelism
👉 Example:
- Spark cluster processing TBs of data
Example (Real-World Scenario)
Centralized Example�
Single Database → Handles all user queries → Limited scale
Distributed Example
Data split across nodes → Parallel processing → Faster results
Example Code (Conceptual)
Centralized Processing
SELECT
region,
SUM(sales)
FROM sales
GROUP BY region;
👉 Runs on single machine
Distributed Processing (Spark Style)
SELECT
region,
SUM(sales)
FROM distributed_sales
GROUP BY region;
👉 Runs across multiple nodes
Performance Reality
Centralized
- Limited by machine capacity
- Can become bottleneck
- Easier debugging
Distributed
- Massive scalability
- Parallel execution
- Network overhead + complexity
👉 Reality: Distributed systems are powerful but hard to design correctly
When to Use Centralized vs Distributed
Use Centralized when:
- Small datasets
- Simple applications
- Low concurrency
Use Distributed when:
- Big data (TBs/PBs)
- High scalability required
- Real-time or heavy workloads
Common Mistakes 🚨
❌ Using Distributed for Small Problems
- Over-engineering
- Unnecessary complexity
❌ Ignoring Fault Tolerance
- Leads to system failures
❌ Poor Data Partitioning
- Causes performance bottlenecks
Interview Angle 🔥
Must-Know Questions
1. Difference between centralized and distributed systems?
👉 Centralized = single node
👉 Distributed = multiple nodes
2. Why use distributed processing?
👉 Scalability and performance
3. Challenges in distributed systems?
👉 Network latency, fault tolerance, consistency
4. Example tools?
👉 Spark, Hadoop, distributed databases
Compare Data Engineering Concepts
FAQ
What is centralized processing?
Processing done on a single system.
What is distributed processing?
Processing spread across multiple systems.
Which is better centralized or distributed?
Depends on scale and requirements.
Why are distributed systems popular?
They scale better for big data.
Comparison Cards (Clean UI)
Centralized
- Single system
- Easy to manage
- Limited scalability
- Low complexity
Distributed
- Multiple nodes
- Highly scalable
- Fault tolerant
- Complex architecture
Final Summary
- Centralized = Simple but limited 🧱
- Distributed = Scalable but complex ⚡
👉 The real skill is knowing when NOT to use distributed systems